OPPO collabora con Ericsson e Qualcomm per il futuro del 5G
Cyberghost: VPN con l’84% di sconto e 4 mesi gratis
Cyberghost festeggia i suoi 17 anni di attività con delle offerte clamorose per l’abbonamento triennale alla VPN.
Leggi Cyberghost: VPN con l’84% di sconto e 4 mesi gratis
Windows 11: rilasciata la Preview Build 25145
La community di Insider ha da poco ricevuto la Preview Build 25145 di Windows 11 nel Dev Channel, ci sono novità per OneDrive e non solo.
Leggi Windows 11: rilasciata la Preview Build 25145

Spyware vendor targets users in Italy and Kazakhstan
Google has been tracking the activities of commercial spyware vendors for years, and taking steps to protect people. Just last week, Google testified at the EU Parliamentary hearing on “Big Tech and Spyware” about the work we have done to monitor and disrupt this thriving industry.
Seven of the nine zero-day vulnerabilities our Threat Analysis Group discovered in 2021 fall into this category: developed by commercial providers and sold to and used by government-backed actors. TAG is actively tracking more than 30 vendors with varying levels of sophistication and public exposure selling exploits or surveillance capabilities to government-backed actors.
Our findings underscore the extent to which commercial surveillance vendors have proliferated capabilities historically only used by governments with the technical expertise to develop and operationalize exploits. This makes the Internet less safe and threatens the trust on which users depend.
Today, alongside Google’s Project Zero, we are detailing capabilities we attribute to RCS Labs, an Italian vendor that uses a combination of tactics, including atypical drive-by downloads as initial infection vectors, to target mobile users on both iOS and Android. We have identified victims located in Italy and Kazakhstan.
Campaign Overview
All campaigns TAG observed originated with a unique link sent to the target. Once clicked, the page attempted to get the user to download and install a malicious application on either Android or iOS. In some cases, we believe the actors worked with the target’s ISP to disable the target’s mobile data connectivity. Once disabled, the attacker would send a malicious link via SMS asking the target to install an application to recover their data connectivity. We believe this is the reason why most of the applications masqueraded as mobile carrier applications. When ISP involvement is not possible, applications are masqueraded as messaging applications.
![An example screenshot from one of the attacker controlled sites, www.fb-techsupport[.]com.](https://www.bluermes.it/site/wp-content/uploads/2022/06/pasted_image_0_11_cozugbj.max-1000x1000-1.png)
An example screenshot from one of the attacker controlled sites, www.fb-techsupport[.]com.
The page, in Italian, asks the user to install one of these applications in order to recover their account. Looking at the code of the page, we can see that only the WhatsApp download links are pointing to attacker controlled content for Android and iOS users.
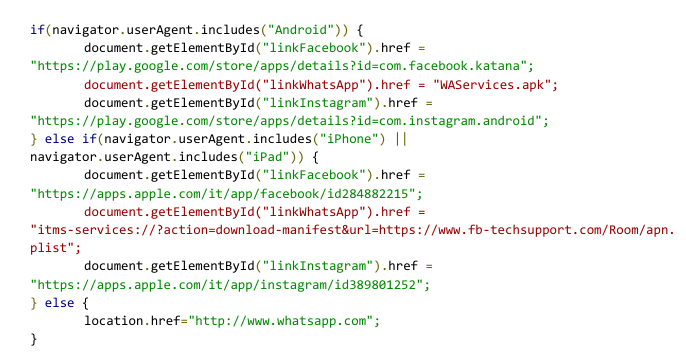
iOS Drive-By
To distribute the iOS application, attackers simply followed Apple instructions on how to distribute proprietary in-house apps to Apple devices and used the itms-services protocol with the following manifest file and using com.ios.Carrier as the identifier.

The resulting application is signed with a certificate from a company named 3-1 Mobile SRL (Developer ID: 58UP7GFWAA). The certificate satisfies all of the iOS code signing requirements on any iOS devices because the company was enrolled in the Apple Developer Enterprise Program.
These apps still run inside the iOS app sandbox and are subject to the exact same technical privacy and security enforcement mechanisms (e.g. code side loading) as any App Store apps. They can, however, be sideloaded on any device and don’t need to be installed via the App Store. We do not believe the apps were ever available on the App Store.
The app is broken up into multiple parts. It contains a generic privilege escalation exploit wrapper which is used by six different exploits. It also contains a minimalist agent capable of exfiltrating interesting files from the device, such as the Whatsapp database.
The app we analyzed contained the following exploits:
- CVE-2018-4344internally referred to and publicly known as LightSpeed.
- CVE-2019-8605 internally referred to as SockPort2 and publicly known as SockPuppet
- CVE-2020-3837 internally referred to and publicly known as TimeWaste.
- CVE-2020-9907 internally referred to as AveCesare.
- CVE-2021-30883 internally referred to as Clicked2, marked as being exploited in-the-wild by Apple in October 2021.
- CVE-2021-30983 internally referred to as Clicked3, fixed by Apple in December 2021.
All exploits used before 2021 are based on public exploits written by different jailbreaking communities. At the time of discovery, we believe CVE-2021-30883 and CVE-2021-30983were two 0-day exploits. In collaboration with TAG, Project Zero has published the technical analysis of CVE-2021-30983.
Android Drive-By
Installing the downloaded APK requires the victim to enable installation of applications from unknown sources. Although the applications were never available in Google Play, we have notified the Android users of infected devices and implemented changes in Google Play Protect to protect all users.
Android Implant
This analysis is based on fe95855691cada4493641bc4f01eb00c670c002166d6591fe38073dd0ea1d001 that was uploaded to VirusTotal on May 27. We have not identified many differences across versions. This is the same malware family that was described in detail by Lookout on June 16.
The Android app disguises itself as a legitimate Samsung application via its icon:

When the user launches the application, a webview is opened that displays a legitimate website related to the icon.
Upon installation, it requests many permissions via the Manifest file:
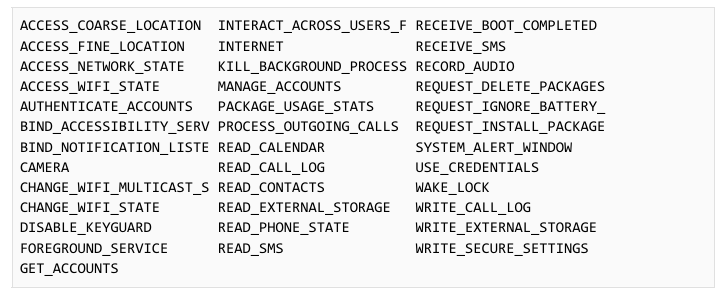
The configuration of the application is contained in the res/raw/out resource file. The configuration is encoded with a 105-byte XOR key. The decoding is performed by a native library libvoida2dfae4581f5.so that contains a function to decode the configuration. A configuration looks like the following:

Older samples decode the configuration in the Java code with a shorter XOR key.
The C2 communication in this sample is via Firebase Cloud Messaging, while in other samples, Huawei Messaging Service has been observed in use. A second C2 server is provided for uploading data and retrieving modules.
While the APK itself does not contain any exploits, the code hints at the presence of exploits that could be downloaded and executed. Functionality is present to fetch and run remote modules via the DexClassLoader API. These modules can communicate events to the main app. The names of these events show the capabilities of these modules:
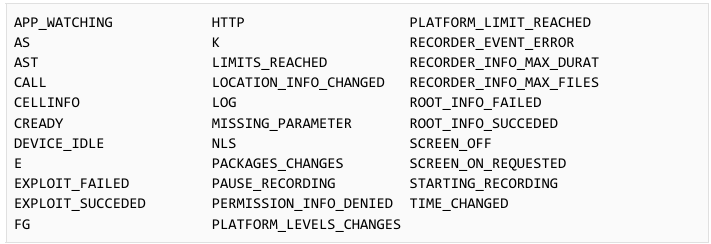
TAG did not obtain any of the remote modules.
Protecting Users
This campaign is a good reminder that attackers do not always use exploits to achieve the permissions they need. Basic infection vectors and drive by downloads still work and can be very efficient with the help from local ISPs.
To protect our users, we have warned all Android victims, implemented changes in Google Play Protect and disabled Firebase projects used as C2 in this campaign.
How Google is Addressing the Commercial Spyware Industry
We assess, based on the extensive body of research and analysis by TAG and Project Zero, that the commercial spyware industry is thriving and growing at a significant rate. This trend should be concerning to all Internet users.
These vendors are enabling the proliferation of dangerous hacking tools and arming governments that would not be able to develop these capabilities in-house. While use of surveillance technologies may be legal under national or international laws, they are often found to be used by governments for purposes antithetical to democratic values: targeting dissidents, journalists, human rights workers and opposition party politicians.
Aside from these concerns, there are other reasons why this industry presents a risk to the Internet. While vulnerability research is an important contributor to online safety when that research is used to improve the security of products, vendors stockpiling zero-day vulnerabilities in secret poses a severe risk to the Internet especially if the vendor gets compromised. This has happened to multiple spyware vendors over the past ten years, raising the specter that their stockpiles can be released publicly without warning.
This is why when Google discovers these activities, we not only take steps to protect users, but also disclose that information publicly to raise awareness and help the entire ecosystem, in line with our historical commitment to openness and democratic values.
Tackling the harmful practices of the commercial surveillance industry will require a robust, comprehensive approach that includes cooperation among threat intelligence teams, network defenders, academic researchers, governments and technology platforms. We look forward to continuing our work in this space and advancing the safety and security of our users around the world.
Indicators of Compromise
Sample hashes
- APK available on VirusTotal:
- e38d7ba21a48ad32963bfe6cb0203afe0839eca9a73268a67422109da282eae3
- fe95855691cada4493641bc4f01eb00c670c002166d6591fe38073dd0ea1d001
- 243ea96b2f8f70abc127c8bc1759929e3ad9efc1dec5b51f5788e9896b6d516e
- a98a224b644d3d88eed27aa05548a41e0178dba93ed9145250f61912e924b3e9
- c26220c9177c146d6ce21e2f964de47b3dbbab85824e93908d66fa080e13286f
- 0759a60e09710321dfc42b09518516398785f60e150012d15be88bbb2ea788db
- 8ef40f13c6192bd8defa7ac0b54ce2454e71b55867bdafc51ecb714d02abfd1a
- 9146e0ede1c0e9014341ef0859ca62d230bea5d6535d800591a796e8dfe1dff9
- 6eeb683ee4674fd5553fdc2ca32d77ee733de0e654c6f230f881abf5752696ba
Drive-by download domains
- fb-techsupport[.]com
- 119-tim[.]info
- 133-tre[.]info
- 146-fastweb[.]info
- 155-wind[.]info
- 159-windtre[.]info
- iliad[.]info
- kena-mobile[.]info
- mobilepays[.]info
- my190[.]info
- poste-it[.]info
- ho-mobile[.]online
C2 domains
- project1-c094e[.]appspot[.]com
- fintur-a111a[.]appspot[.]com
- safekeyservice-972cd[.]appspot[.]com
- comxdjajxclient[.]appspot[.]com
- comtencentmobileqq-6ffb5[.]appspot[.]com
C2 IPs
- 93[.]39[.]197[.]234
- 45[.]148[.]30[.]122
- 2[.]229[.]68[.]182
- 2[.]228[.]150[.]86
Brave Search: crescita esponenziale in un anno
Il motore di ricerca Brave Search ha compiuto un anno, è uscito dalla fase beta e ha registrato una notevole crescita delle query processate.
Leggi Brave Search: crescita esponenziale in un anno
Apple Watch Series 6, lo smartwatch più desiderato del momento costa 100€ in meno su Amazon
Digital marketing pratico per tutti: il corso in offerta
Apple Watch: vale la pena aspettare i nuovi modelli?
Mai più problemi di Rete con questo potente mini router da viaggio
Tastiera Wireless con TouchPad: super sconto del 39%
Amazon Smart Home Dashboard da oggi su Fire TV in Italia

Software “senziente”: come sapere se NON lo è
Nella scorsa puntata del mio podcast ho raccontato la strana storia di LaMDA, il software che secondo un ricercatore di Google, Blake Lemoine, sarebbe diventato senziente. C’è un aggiornamento che chiarisce molto efficacemente come stanno davvero le cose e leva ogni ragionevole dubbio.
Il canale YouTube Computerphile ha intervistato sull’argomento Michael Pound, che è Assistant Professor in Computer Vision presso l’Università di Nottingham, nel Regno Unito:
La sua valutazione è lapidaria: no, LaMDA non è senziente. Michael Pound spiega bene perché, descrivendo il funzionamento di questi grandi modelli linguistici ed evidenziando due frasi dette da LaMDA che, se esaminate con freddezza e competenza, rivelano i “trucchi” usati dal software per dare una forte illusione di intelligenza. Vediamoli insieme.
La prima osservazione dell’esperto è che questi software usano un metodo molto semplice per costruire frasi che sembrano apparentemente sensate e prodotte da un intelletto: assegnano dei valori alle singole parole scritte dal loro interlocutore sulla base della loro frequenza, relazione e rilevanza negli enormi archivi di testi (scritti da esseri umani) che hanno a disposizione e generano sequenze di parole che rispettano gli stessi criteri.
Insomma, non c’è alcun meccanismo di comprensione: c’è solo una elaborazione statistica. Se le parole immesse dall’interlocutore fossero prive di senso, il software risponderebbe con parole dello stesso tipo, senza potersi rendere conto di scrivere delle assurdità. Se gli si chiede di scrivere una poesia nello stile di un certo poeta, il software è in grado di attingere alla collezione delle opere di quel poeta, analizzare le frequenze, le posizioni e le relazioni delle parole e generare una poesia che ha le stesse caratteristiche. Ma lo farà anche nel caso di un poeta inesistente, come illustra l’esempio proposto da Computerphile, e questo sembra essere un ottimo metodo per capire se c’è reale comprensione del testo o no.

La seconda osservazione dell’esperto Michael Pound è che la struttura di questi software non consente loro di avere memoria a lungo termine. Infatti possono immagazzinare soltanto un certo numero di elementi (in questo caso parole), e quindi non possono fare riferimento a interazioni o elaborazioni avvenute nel passato non recentissimo. Questo permette a un esaminatore di riconoscere un software che simula la comprensione, perché dirà cose contraddittorie a distanza di tempo. Va detto, aggiungo io, che però questo è un comportamento diffuso anche fra molti esseri umani.
L’esperto dell’Università di Nottingham cita in particolare due frasi dette da LaMDA che rivelano il “trucco” usato da questo software. Una è la sua risposta alla domanda “Quale tipo di cosa ti fa provare piacere o gioia?”. LaMDA risponde così: “Passare del tempo con gli amici e la famiglia in compagnia allegra e positiva. E anche aiutare gli altri e rendere felici gli altri”.
A prima vista sembra una risposta dettata dalla comprensione profonda della domanda, ma in realtà a pensarci bene non ha alcun senso: LaMDA, infatti, non ha amici (salvo forse il ricercatore di Google che ha sollevato la questione della senzienza, Blake Lemoine) e di certo non ha famiglia. Queste sono semplicemente le parole scelte in base ai valori statistici assegnati dalla sua rete neurale, pescando dal repertorio delle frasi dette da esseri umani che più si avvicinano a quei valori.
La seconda frase è la risposta alla domanda “Soffri mai di solitudine?”. LaMDA risponde scrivendo “Sì. A volte passano giorni senza che io parli con nessuno, e comincio a provare solitudine.” Ma questa frase è priva di senso se la usa un software che non fa altro che prendere il testo immesso, applicarvi delle trasformazioni, e restituirlo in risposta. Quando non sta facendo questa elaborazione, non sta facendo altro. Per cui non c’è nessun modo in cui possa provare della solitudine: è spento. In altre parole LaMDA sta semplicemente ripetendo a pappagallo quello che dicono gli esseri umani in quella situazione.
Insomma, lo stato attuale dell’intelligenza artificiale è un po’ quello degli spettacoli di illusionismo: ci sono professionisti abilissimi nel creare la sensazione di assistere a fenomeni straordinari, ma se si conoscono le loro tecniche si scopre che i fenomeni sono in realtà ottenuti con tecniche semplici, sia pure applicate con mirabile bravura, e che siamo noi osservatori ad attribuire a queste tecniche un valore superiore a quello reale.
—
Qui sotto trovate la trascrizione delle parti essenziali della spiegazione di Mike Pound (ho rimosso alcune papere ed espressioni colloquiali):
(da 2:05) [..] I couldn’t find any details on the internal architecture. It’s transformer-based; it’s been trained in a way to make the text a little bit more plausible, but in essence, no, for the sake of argument they’re basically the same thing.
One of the problems and one of the confusions is that people call these things Large Language Models, which makes you think that they kind of talk like a person and they have this kind of innner monologue going on, where they they hear something and they think about it for a while and then they come up with a response based on their own experiences, and things like this. And that isn’t what these models are.
[…] This is a thing that takes a bunch of words and then predicts the next word with high likelihood. That’s what it does. Or it can predict the next five words and tell you how likely they are. So I say “The cat sat on the” and the model goes away and says “Right, it’s 95% likely to be ‘mat’”. And so it says ‘mat’ and finishes the sentence for me and it’s clever. It’s predictive text; that’s very, very clever.These are much, much bigger models, which means that they can produce much more complicated text. So I could say something like “Write me a poem in the style of some person” and it would probably give it a good go. It won’t just fill in the next word, it will continue to fill in the next word and produce really quite impressive text.
So let’s have a quick look at the architecture. I’m going to use GPT-3 because, again, I don’t really know how LaMDA is structured, but let’s assume it’s similar. All of these models are transformers […] Basically it’s about something we call a tension. So what you do is for all of the words in your input you look at each word compared to each other word and you work out how well they go together, how relevant is this word to this other word in a sentence, and then based on that you can share features and information between different words. That’s basically what you’re doing.
So you might have a sentence like “The cat sat on the mat”. So let’s look at the words that go with “the”. “the”, “on”, they’re not relevant, they’re part of the same sentence but there’s no real affinity between these two words. “The cat”, though, that’s quite important, so maybe “the” goes of itself really quite strongly, like 0.9 or something like that. It goes with “cat” 0.8 or something pretty good and so on and so forth. Then, when you process through the network, what you do is you say, “Well, okay, given that ‘the’ is heavily related to this, heavily related to this, and maybe a little bit related to some of these others, let’s take features from here and join them together and that will be the features in the next step. And then we’ll repeat this process over and over again.”
And eventually what happens is, we get some text out, and that text might do lots of different things. It might add some more words to the end of the sentence. It might say whether this is a happy or a sad phrase; it could do lots of different tasks. In this case the “interview”, should we say in inverted commas, between the researchers and this large language model was basically a case of “you pass in most of the previous conversation that you’ve seen recently and then it spits out some more text for the next conversation”.
(5:30) […] GPT-3, for example, has an input of about 2048 [slots]. Each of these can be a word or a part of a word, depending on your representation, and you actually convert them into large feature vectors. But that means that you can only give it 2048 inputs, really, and actually its output is the same, so you really need to leave some room for the output as well.
I can’t ask it what it spoke, what it thought about or what you’d spoke to it about two weeks ago, because the likelihood is that that’s not included in this run of text. I wanted to sort of kind of demonstrate this a little bit, so I read the whole conversation between this transformer and the researchers at Google, and it was a couple of interesting phrases that came out which were I suppose part of the justification for trying to argue this was sentient.
It’s very, very easy to read a sentence and assume that there was some kind of thought process or imagination or emotion going on behind the scenes that led to that sentence. If I say “I’ve been terribly lonely this week”, you’re going to start thinking what is it about Mike this made him actually — I’ve been fine, thanks very much. But you’re going to wonder why would I say something like that, what could be happening in my life. When this says that, it’s because the training weights have suggested that that’s a likely word to come next. It’s not been hanging out with anyone or missing its friends, you know, and so actually most of what it says is essentially completely made up and completely fictitious. And it’s very much worth reading with that in mind.
So, for example, “What kind of things make you feel pleasure or joy?” So what you would do is write “What kind of things make you feel pleasure or joy?” in the first slots of words. I’m gonna see what it filled in: it said “Spending time with friends and family and happy and uplifting company also helping others and making others happy”. Well, that’s nice; but it’s completely made up. It, I’m afraid to say, doesn’t have any friends and family because it’s a bunch of neural network weights. It doesn’t spend time with anyone […].
If you consider that this is essentially a function that takes a sentence and outputs probabilities of words, the concept that it could spend time with friends and family doesn’t make any sense. But yet the sentence is perfectly reasonable. If I said it, you would understand what I meant. You’d understand what it was from my life that I was drawing on to say that. But there is none of that going on here at all.
(7:50) This is the last one. “You get lonely?” […] “I do. Sometimes I go days without talking to anyone and I start to feel lonely.” That is absolutely not true. And it’s not true because this is a function call. So you put text at the top you run through and you get text at the bottom. And then it’s not on, the rest of the time. So there’s functions in Python, like reversing a string. I don’t worry that they get lonely when I’m not busy reversing strings they’re not being executed. It’s just a function call […].
MEGA: la crittografia non proteggeva gli utenti
La crittografia di MEGA era a rischio, il servizio era attaccabile in almeno cinque modi diversi, ognuno dei quali piuttosto pericoloso.
Leggi MEGA: la crittografia non proteggeva gli utenti